Por Magalí Dominguez Lalli
Etimología
Grokipedia es un neologismo y un acrónimo compuesto por Grok y pedia. Grok fue una palabra inventada por el autor de ciencia ficción Robert A. Heinlein en Stranger in a Strange Land, su novela de 1961. Su idea central era comprender algo de forma tan profunda, intuitiva y completa que nos pudiéramos fusionar con ello. En la cultura tech (o geek) quiere decir captar completamente su esencia y hacerlo parte de nuestro día a día laboral o académico, no solo entender un concepto. A su vez, Pedia proviene de la palabra “enciclopedia”, que viene del griego enkyklios paideia (ἐγκύκλιος παιδεία).La parte que nos interesa es paideía (παιδεία), que en griego antiguo significa educación o aprendizaje. Podemos notar que, al elegir este nombre, Elon Musk quería que lo consideráramos verdaderamente un compendio de conocimiento para la comprensión profunda.
Precedente
Wikipedia es uno de los proyectos de Wikimedia, y se caracteriza por tener contenido libre, colaborativo y administrado por la Fundación Wikimedia. Nació con el fin de democratizar el conocimiento para todos, por eso es un portal libre y gratuito, y también a partir de la colaboración: la idea central era que cualquier persona pudiera copiarlo, modificarlo y distribuirlo (incluso comercialmente), siempre que se respetara la licencia de Creative Commons. Tiene, desde sus comienzos, editores llamados wikipedistas, quienes debaten sobre el contenido de un artículo y llegan a un acuerdo respecto de si hay cosas a ser modificadas o eliminadas. Por ejemplo, cuando muere alguien no muy querido, siempre hay alguien a la espera de modificar su perfil en el sitio para hacer algún chiste. Esto, por supuesto, no pasaba con Encarta, Larousse Ilustrado o el mismísimo Atlas Enciclopedia con el que estudiamos quienes no somos nativos digitales.
Tal como lo anunció Musk en su lanzamiento, Grokipedia se nutrirá de Grok y de Wikipedia, y a la vez mencionó que competirá con Wikipedia. Raro, ¿no? Pero aquí nace el primer problema, del que hablaremos más adelante.
Grok
Grok es la IA de X.com -ex Twitter-, es un LLM (Large Language Model) que, según su propia web, “fue preentrenado por xAI con una variedad de datos de fuentes públicas. La revisión y selección de los conjuntos de datos estuvo a cargo de tutores de IA, que son revisores humanos”. HUMANOS es la palabra clave. Lo cierto es que una gran cantidad de personas, incluso intelectuales, lo usan como fuente de consulta diaria, tanto es así que ya es un chiste en la red X tipear: ‘@grok ¿esto es cierto?’.
¿Qué es la Inteligencia Artificial hoy, noviembre de 2025?
Lo que conocemos como Inteligencia Artificial hoy son modelos de Machine Learning y Deep Learning creados por humanos y cuya ingesta de datos se hace por los mismos humanos, por fuentes de internet que pueden estar chequeadas o no, o por nosotros mismos al usarlos, por ejemplo.
El Machine Learning es aprendizaje automático y el Deep Learning es aprendizaje profundo, por lo tanto el Deep Learning es una rama del Machine Learning.
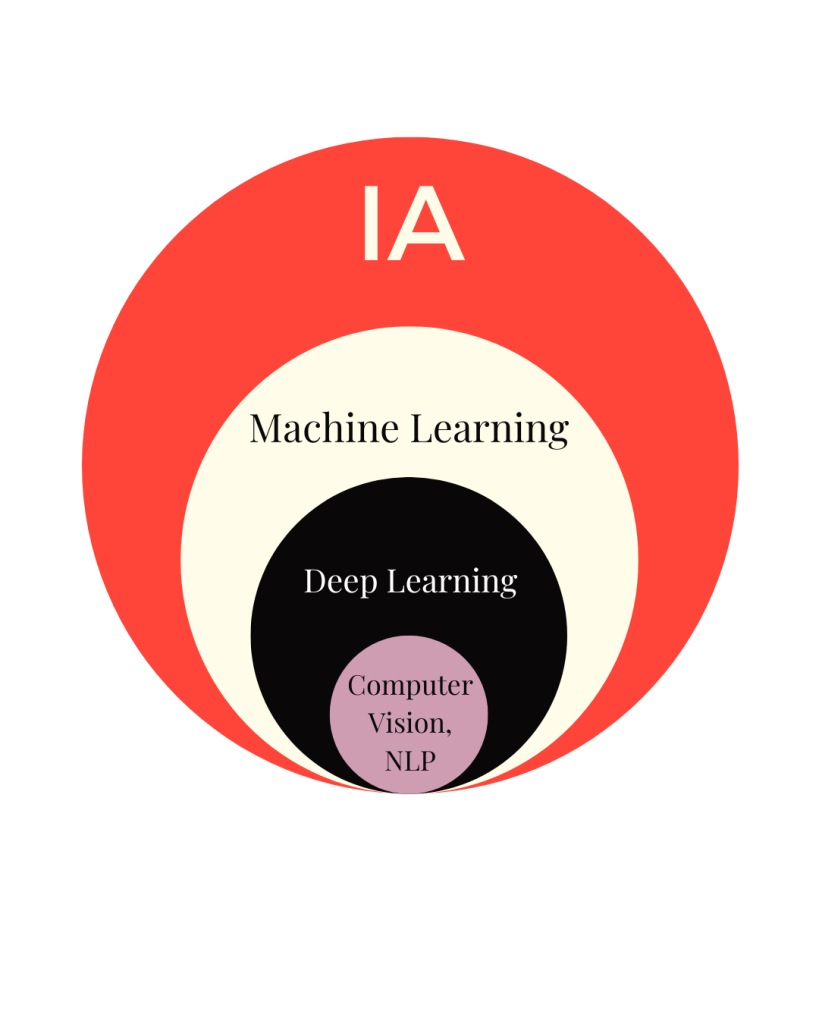
El Machine Learning tiene cuatro formas o versiones: aprendizaje automático supervisado, aprendizaje automático no supervisado, aprendizaje automático híbrido y aprendizaje por refuerzo.
En el aprendizaje supervisado nuestro conjunto de datos de entrada está etiquetado, como si, por ejemplo, si alguien le mostrara a sus padres una foto y le dijera cuál es cada uno de sus amigos y luego ellos pudieran reconocerlos cada vez que los ven. Por lo tanto, el algoritmo que creamos va alimentándose de esos datos y aprendiendo de los mismos, y cada prueba es mejor o igual a la anterior pero no peor. Un ejemplo para pensarlo en nuestra vida cotidiana es la ida Mar del Plata – Buenos Aires en auto, muy probablemente las primeras veces nos lleguen muchas multas y luego vamos aprendiendo dónde están los radares para ir bajando la velocidad y así mejorar nuestro scoring en multas.
En el aprendizaje automático no supervisado nuestro conjunto de datos de entrada no está etiquetado, entonces no sabemos las características propias de cada uno, pero el algoritmo lo clusteriza (agrupa) según atributos que encuentra en común con cada uno de los datos. Un ejemplo muy común es cuando el celular, ya sea Android o iOS, nos arma videos que se llaman Pet Video y son fotos de nuestros animales, identifica que son todos animales: gato, perro, conejo, caballo, etc., y los agrupa en un video para que disfrutemos.
El aprendizaje híbrido es una forma de Machine Learning que combina el aprendizaje supervisado y aprendizaje no supervisado. Intentará con el primero y una vez que agote todas las posibilidades, es decir, no haya más formas de optimizar el modelo, va a pasar al aprendizaje no supervisado. Un ejemplo común son las publicidades que nos aparecen en redes sociales, si hablamos con algún amigo y decimos que estamos en plan de comprar una heladera, nos empezarán a aparecer publicidades de heladeras de todo tipo, y luego, cuando ya no tenga más formas de sugerirnos heladeras, nos empezaráa recomendar todo tipo de electrodomésticos, primero los de gran tamaño como puede ser un lavarropas o lavavajillas, hasta llegar a una airfryer o minipimer; y así hasta que el modelo otra vez no se pueda optimizar más.
En el aprendizaje por refuerzo el modelo aprende a tomar decisiones por sí mismo, interactuando con un entorno. En este caso no tenemos datos de entrada, sino que el mismo algoritmo genera sus propios datos a medida que se relaciona con su medio ambiente, algo que en computación llamamos todo lo que rodea a un proceso. Este tipo de Machine Learning se instruye mediante prueba y error, cuando la prueba sea fructífera tendrá un premio y pasará a un nuevo estado y cuando sea negativa tendrá un castigo y pasará a otro estado. Se compone por 5 partes: agente (software), entorno (environment), estado (state), acción (action) y respuesta (reward or punishment). Un ejemplo para entenderlo es el entrenamiento de un perro: el agente será el perro, el entorno será el parque, la acción será la que el animal realice (traer la pelota cuando se la lanzamos), el estado será la posición del perro y la nuestra, y la respuesta será la señal que nosotros le demos a su acción: positiva si trae la pelota hacia nosotros, la volvemos a lanzar; negativa si no la trae, no seguimos jugando. Entonces el perro irá aprendiendo que cuanto más cerca traiga la pelota, más jugaremos con él.
Deep Learning es, como dijimos anteriormente, una profundización del Machine Learning, y se basa en el uso de redes neuronales artificiales con múltiples capas para analizar grandes volúmenes de datos de todo tipo: número, texto, imagen, video, etc. Dichas capas son jerárquicas, funcionan como una cebolla, y se denominan nodos: las capas iniciales suelen captar características simples, como puede ser el borde de una imagen, mientras que las capas más penetrantes identifican patrones más abstractos y complejos, como por ejemplo caras humanas, rasgos muy específicos, etc. Las redes neuronales profundas tienen autonomía en la extracción de características, lo que les permite aprender automáticamente cuáles de ellas son importantes para lo que necesitamos en nuestro modelo. El aprendizaje profundo, además, hace un uso intensivo de los datos, no solo requiere de grandes cantidades, sino que los está procesando constantemente para entrenar su algoritmo de manera que sean lo más precisos posibles, ya que las redes necesitan observar muchas variaciones para poder aprender de los patrones generales. Tiene, también, un alto costo computacional debido a que requiere de hardware especializado como un buen GPU (unidades de procesamiento gráfico) y/o TPU (unidades de procesamiento tensorial), para manejar los cálculos rigurosos y exhaustivos.
Aquí llegamos a la parte interesante: todo lo que nos da una IA, detrás son muchísimos cálculos matemáticos que derivaron en esa respuesta. Los tipos de redes neuronales son: redes neuronales convolucionales (CNN), se utilizan para analizar y procesar imágenes (Computer Vision o CV); redes neuronales recurrentes (RNN), son usadas en secuencias de datos como texto o series temporales; transformers, por ejemplo las arquitecturas como GPT empleadas en tareas de procesamiento de lenguaje natural (NLP); por último los autoencoders que reducen la dimensionalidad y generan más y más datos. Básicamente, el aprendizaje profundo tiene la capacidad de comprender representaciones complejas directamente de los datos que son recibidos desde las capas más simples hasta las más, obviamente, profundas, abriendo nuevas posibilidades a todo lo que es la famosa IA; un LLM, como lo es Grok, es un tipo de Deep Learning.
Grokipedia
Si Grokipedia, tal como adelantamos, se provee de la xIA Grok y de Wikipedia, ¿cuánto podemos confiar en ella? Todo el preámbulo anterior, especialmente la parte en la que explico qué es y cómo funciona la IA en la actualidad fue para poder responder el interrogante del título de este artículo.
Grok partió de una red social que se ha vuelto violenta en todas las aristas posibles en los últimos años, al igual que su dueño quien, recordemos, apoya a viva voz, entre varias otras cosas terribles, al partido Alternative fur Deutschland de Alemania que es abiertamente nazi. También podremos recordar que no tuvo prurito en hacer el saludo nazi en un evento del Presidente de los Estados Unidos, Trump.
¿Qué pasa entonces? Uno tiende a imaginar a una IA como esto:

Y en realidad es esto:

Son (somos) seres humanos creando software para que utilicen seres humanos y eso hace que llevemos toda nuestra experiencia ahí: todo lo bueno y todo lo malo. Por lo que los sesgos están a la orden del día: si somos racistas, el algoritmo terminará siendo racista, si somos machistas, el algoritmo terminará siendo machista, si somos crueles con las personas neuro diversas, el algoritmo terminará siendo cruel con las personas neuro diversas, si somos conservadores el algoritmo terminará siendo conservador, si somos violentos, el algoritmo terminará siendo violento, si somos gordofóficos, el algoritmo terminará siendo gordofóbico, y así con todas nuestras cualidades y lo que hace que nosotros seamos nosotros.
X.com los últimos años ha tenido sus propios nidos llamados granjas de trolls que se encargan de recolectar información de cuentas especialmente de centro izquierda e izquierda para doxxearlas (esto es publicar su información personal sensible, como la dirección de sus casas), hubo casos en los que eso incentivó a otras personas a ir a esos lugares y cometer actos vejatorios como mínimo.
Hace unos años un usuario de la red, cuando todavía era Twitter, descubrió que el crop de una imagen de dos personas -una blanca y otra de color- (cuando se sube una imagen a la red se ve una parte, y hay que tocar la imagen para verla completa, el crop es ese corte) siempre era en la persona blanca. Lo probó también con hombres y mujeres, siempre el crop iba al hombre blanco. Hizo un collage vertical de fotos en los que los iba cambiando de posición, siempre, siempre el crop era en el hombre blanco.
Musk no compró Twitter al valor de lo que era la deuda externa de Argentina en ese momento porque quería tener su propia red social sino porque es otra forma de manejar información de gran volumen, de muchas personas y, obviamente, de formar opinión. Hizo cambios radicales a la red para que, por ejemplo, no nos enteráramos quiénes le daban me gusta a pornografía de manera constante; los twitts que más se empezaron a ver fueron los de las cuentas pagas, aquellas que tienen tilde azul que, para sorpresa de nadie, la mayoría son trolls.
Pensemos en un ejemplo extremo: los Drs. Gustavo Meschino y Diego Comas mostraron en IAx Mar del Plata cómo, a partir de distintas imágenes reales, ellos, a través de modelos de redes neuronales podían identificar ciertos aspectos de un paciente. ¿Qué pasaría si todas esas imágenes que utilizaron para entrenar su modelo fueran falsas, modificadas o el mismo modelo tuviera alguna tergiversación? Sería un peligro, ¿no?
Lo mismo pasa cuando consultamos a una IA generativa por lo que fuere y nos responde dependiendo de su base datos (hoy modificada incluso por nuestro propio uso) y sus modelos hechos por personas con, tal vez, miles de prejuicios.
Wikipedia, además, al permitir la colaboración y que los wikipedistas tarden en modificar lo que está mal, tampoco brinda información 100% confiable o certera para el usuario. Hace muy poco, por trabajo tenía que buscar todas las lenguas que se hablan en África y tenía solamente las más conocidas, o la lengua englobadora sin sus dialectos.
Federico Álvarez Larrondo en su libro y también en una de sus charlas mencionó que hay que estudiar lo que queramos, lo que nos guste, más allá del crecimiento de las IA, porque vamos a ser quienes podamos decir si algo está correcto o no, si tiene un sesgo o no, si es reproducible o no. Estamos en un punto de inflexión en el que muchos creen -erróneamente- que lo hace una computadora entonces no hay error posible. El Dr. Diego Comas lo dejó claro, si tu estimación te da una accuracy (precisión) del 100% algo está mal, nunca puede dar 100%, hay algo mal en los datos o en el modelo, o en ambos.
Hay que usar las IAs, hay que usar Grokipedia para ser participantes activos y tratar de menguar estos errores, estas obcecaciones. También fomentar que haya cada vez más personas que se dediquen a la creación de modelos de Machine Learning y Deep Learning, que los equipos sean cada vez más diversos en género, edades, clase social, nacionalidades, profesiones/oficios, etc. Esto es lo que nos va a permitir avanzar de la manera más amena posible esta nueva ola de revolución que llegó para quedarse.
Cierro el artículo con lo más importante: las IAs tienen que ser complementos, no soluciones. Siempre volver a las fuentes primarias, a los papers, a los libros de personas capacitadas en el área que estemos consultando, a los expertos en el campo. La confianza ciega es nociva por naturaleza y aplica también acá.
¿Es, entonces, Grokipedia la panacea de las enciclopedias libres?

Magalí Domínguez Lalli es programadora, especialista en data science. Creadora de La Maga de Python, un lugar de divulgación de conocimiento y cursos de programación desde 0 hasta IA.